KAPDEC® | Elite STEM Learning Platform | https://kapdec.com
Unit: Statistics and Probability
Chapter: Mean, Mode, Median Graphical Representation of Frequency Distribution
Reference: – Introduction to Statistics, Measures of Central Tendency, Mean (Arithmetic Mean), Median, Mode, Graphical Representation: Bar Graphs, Histograms, Frequency Polygons, Ogives (Cumulative Frequency Curves), Comparison and Application
After studying this chapter, you should be able to understand:
- The concepts of mean, median, and mode as measures of central tendency.
- How to calculate mean, median, and mode for grouped and ungrouped data.
- Various methods of graphical representation of data.
- How to interpret and compare different types of graphs.
Introduction to Statistics
Definition
Statistics is the branch of mathematics that deals with the collection, organization, analysis, interpretation, and presentation of data. It helps in summarizing and describing the main features of a collection of information.
The primary goal is to make sense of data and draw meaningful conclusions from it.
[Importance of Statistics]
- Used in various fields like economics, business, science, and social sciences.
- Helps in decision-making based on data analysis.
- Essential for research and forecasting.
- Enables comparison between different sets of data.
Example
Data Set: The test scores of 10 students: 85, 90, 78, 92, 88, 76, 95, 89, 84, 91.
We can find the average score, the most frequent score, and the middle score
[Subtopics]
1. Types of Data
- Ungrouped Data: Raw data without any intervals.
- Grouped Data: Data organized into classes or intervals.
Key Points:
- Frequency: The number of times a particular value occurs.
- Class Interval: A range of values used for grouping data.
- Class Mark: The midpoint of a class interval.
Measures of Central Tendency
[Definition]
Measures of central tendency are statistical measures that represent the center point or typical value of a dataset. The three main measures are Mean, Median, and Mode.
[Importance of Central Tendency]
- Provides a single value that represents the entire dataset.
- Helps in summarizing large sets of data.
- Useful for comparing different datasets.
- Forms the basis for more complex statistical analysis.
Examples
- For the data set: 2, 3, 3, 5, 7, the mean is 4, the median is 3, and the mode is 3.
[Subtopics]
1. Mean (Arithmetic Mean)
The mean is the average of all the values in the dataset.
- For Ungrouped Data:
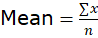
Source: Kapdec.com
, where ∑x is the sum of all values and n is the number of values.
- For Grouped Data:
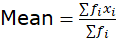
Source: Kapdec.com
, where
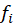
Source: Kapdec.com
is the frequency of the i-th class and
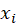
Source: Kapdec.com
is the class mark.
2. Median
The median is the middle value when the data is arranged in ascending or descending order.
- For Ungrouped Data:
- If n is odd: Median =
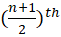
Source: Kapdec.com
value.
- If n is even: Median = average of
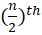
Source: Kapdec.com
and
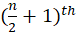
Source: Kapdec.com
values.
- If n is odd: Median =
- For Grouped Data:
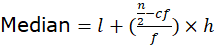
Source: Kapdec.com
, where l is the lower limit of the median class, cf is the cumulative frequency of the class preceding the median class, f is the frequency of the median class, and h is the class width.
3. Mode
The mode is the value that appears most frequently in the dataset.
- For Ungrouped Data: The value with the highest frequency.
- For Grouped Data:
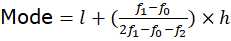
Source: Kapdec.com
, where l is the lower limit of the modal class,
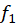
Source: Kapdec.com
is the frequency of the modal class,
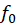
Source: Kapdec.com
is the frequency of the class preceding the modal class,
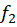
Source: Kapdec.com
is the frequency of the class succeeding the modal class, and h is the class width.
Mean (Arithmetic Mean)
[Definition]
The arithmetic mean is the sum of all values divided by the number of values. It is the most commonly used measure of central tendency.
[Importance of Mean]
- Uses all values in the dataset.
- Easy to understand and calculate.
- Suitable for further statistical analysis.
Examples
- Find the mean of the numbers: 10, 20, 30, 40, 50.
[Subtopics]
1. Calculation for Ungrouped Data
Source: Kapdec.com
2. Calculation for Grouped Data
Using the formula
Source: Kapdec.com
.
Median
[Definition]
The median is the value that separates the higher half from the lower half of the data set. It is less affected by extreme values (outliers) than the mean.
[Importance of Median]
- Provides a better measure for skewed distributions.
- Useful when extreme values are present.
- Easy to find for ordinal data.
Examples
- Find the median of: 12, 15, 18, 20, 25.
[Subtopics]
1. Calculation for Ungrouped Data
Arrange in order: 12, 15, 18, 20, 25. n=5 (odd), so Median = 3rd value = 18.
2. Calculation for Grouped Data
Using the formula
Source: Kapdec.com
.
Mode
[Definition]
The mode is the value that occurs most frequently in the data set. A dataset may have one mode, more than one mode, or no mode at all.
[Importance of Mode]
- Useful for categorical data.
- Helps in identifying the most popular or common value.
- Easy to find for nominal data.
Examples
- Find the mode of: 2, 3, 4, 4, 5, 5, 5, 6, 7.
[Subtopics]
1. Calculation for Ungrouped Data
The value 5 appears three times, so Mode = 5.
2. Calculation for Grouped Data
Using the formula
Source: Kapdec.com
.
Graphical Representation of Frequency Distribution
[Definition]
Graphical representation involves displaying data in visual forms such as graphs and charts. This makes it easier to understand patterns, trends, and comparisons in the data.
[Importance of Graphical Representation]
- Provides a quick overview of the data.
- Helps in identifying patterns and outliers.
- Makes complex data more understandable.
- Useful for presentations and reports.
Examples
- Represent the frequency distribution of test scores using a histogram.
[Subtopics]
1. Bar Graph
A graph that uses bars to represent frequencies of different categories. The bars can be vertical or horizontal.
2. Histogram
A graph that uses bars to represent frequencies of continuous data in class intervals. There are no gaps between the bars.
3. Frequency Polygon
A line graph formed by joining the midpoints of the tops of the bars in a histogram.
4. Ogive (Cumulative Frequency Curve)
A graph that represents cumulative frequencies for class intervals. It can be “less than” or “more than” type.
Comparison and Application
[Definition]
This involves comparing the different measures of central tendency and graphical representations to choose the most appropriate one for a given dataset. It also includes applying these concepts to solve real-world problems.
[Importance of Comparison and Application]
- Helps in selecting the best measure for a given situation.
- Enhances critical thinking and analytical skills.
- Prepares for practical data analysis in various fields.
Examples
- Determine which measure of central tendency is most appropriate for a given dataset.
[Subtopics]
1. When to Use Mean, Median, or Mode
- Mean: When data is symmetric and without outliers.
- Median: When data is skewed or has outliers.
- Mode: When dealing with categorical data or identifying the most frequent value.
2. Choosing the Right Graph
- Bar Graph: For categorical data.
- Histogram: For continuous data.
- Frequency Polygon: To show trends in continuous data.
- Ogive: To determine medians, quartiles, and percentiles.
[Example: -]
Problem Statement:
The following table shows the distribution of marks obtained by 50 students in a mathematics test.
|
Marks (Class Interval) |
0-10 |
10-20 |
20-30 |
30-40 |
40-50 |
|
Number of Students (f) |
5 |
10 |
18 |
12 |
5 |
Source: Kapdec.com
a) Find the mean marks.
b) Find the median marks.
c) Find the modal marks.
d) Draw a histogram and frequency polygon for the data.
Question: Solve parts (a) to (c) and describe the construction for (d). Prove your answers by providing a step-by-step solution and giving three independent reasons supporting your conclusion for part (a) from these domains: (A) Direct Formula Application, (B) Assumed Mean Method, (C) Step-Deviation Method.
[Solution: -]
Given: Frequency distribution table.
Step 1: Prepare the table for calculations.
We need class marks (x_i) for mean.
|
Class Interval |
Frequency (f_i) |
Class Mark (x_i) |
f_i * x_i |
Cumulative Frequency (cf) |
|
0-10 |
5 |
5 |
25 |
5 |
|
10-20 |
10 |
15 |
150 |
15 |
|
20-30 |
18 |
25 |
450 |
33 |
|
30-40 |
12 |
35 |
420 |
45 |
|
40-50 |
5 |
45 |
225 |
50 |
|
Total |
Σf_i = 50 |
Σf_i x_i = 1270 |
Source: Kapdec.com
a) Find the mean marks.
(A) Direct Formula Application
Mean using direct method:
Source: Kapdec.com
Source: Kapdec.com
So, the mean marks are 25.4.
(B) Assumed Mean Method
Let Assumed Mean (A) = 25.
Calculate deviations d_i = x_i – A.
|
x_i |
f_i |
d_i = x_i – 25 |
f_i * d_i |
|
5 |
5 |
-20 |
-100 |
|
15 |
10 |
-10 |
-100 |
|
25 |
18 |
0 |
0 |
|
35 |
12 |
10 |
120 |
|
45 |
5 |
20 |
100 |
|
Total |
Σf_i d_i = 20 |
Source: Kapdec.com
Mean =
Source: Kapdec.com
This confirms the mean.
(C) Step-Deviation Method
Let Assumed Mean (A) = 25. Class width (h) = 10.
Calculate
Source: Kapdec.com
.
|
x_i |
f_i |
u_i = (x_i – 25)/10 |
f_i * u_i |
|
5 |
5 |
-2 |
-10 |
|
15 |
10 |
-1 |
-10 |
|
25 |
18 |
0 |
0 |
|
35 |
12 |
1 |
12 |
|
45 |
5 |
2 |
10 |
|
Total |
Σf_i u_i = 2 |
Source: Kapdec.com
Mean =
Source: Kapdec.com
This provides a third verification.
b) Find the median marks.
Total number of students, n = 50.,
Source: Kapdec.com
.
The cumulative frequency just greater than or equal to 25 is 33. So, the median class is 20-30.
- l (lower limit) = 20
- cf (cumulative frequency of preceding class) = 15
- f (frequency of median class) = 18
- h (class width) = 10
Median =
Source: Kapdec.com
=
Source: Kapdec.com
So, the median marks are approximately 25.56.
c) Find the modal marks.
The class with the highest frequency is 20-30 (f=18). So, the modal class is 20-30.
- l = 20
- f_1 = 18
- f_0 = 10 (frequency of preceding class)
- f_2 = 12 (frequency of succeeding class)
- h = 10
Mode =
Source: Kapdec.com
=
Source: Kapdec.com
=
Source: Kapdec.com
So, the modal marks are approximately 25.71.
d) Draw a histogram and frequency polygon.
Histogram:
- On the x-axis, take the class intervals (0-10, 10-20, etc.).
- On the y-axis, take the frequencies (5, 10, 18, etc.).
- Draw bars for each class interval with heights corresponding to their frequencies. Since class widths are equal, the bars will have proportional heights.
Frequency Polygon:
- Find the class marks: 5, 15, 25, 35, 45.
- Plot points at (class mark, frequency): (5,5), (15,10), (25,18), (35,12), (45,5).
- Join these points with straight lines.
- To close the polygon, also plot points at the previous and next class marks with zero frequency: (-5,0) and (55,0), and connect them.
Final Answers:
a) Mean = 25.4
b) Median ≈ 25.56
c) Mode ≈ 25.71
d) Histogram and frequency polygon as described.
The mean calculation is rigorously confirmed by three independent methods: Direct, Assumed Mean, and Step-Deviation.
Scan to visit this resource online
https://kapdec.com/resources/mean-mode-median-graphical-representation-of-frequency-distribution
